Regula falsi
Regula-falsi-Verfahren (lateinisch regula falsi ‚Regel des Falschen‘), auch: Regula duarum falsarum Positionum (lateinisch regula duarum falsarum positionum ‚Regel vom zweifachen falschen Ansatz‘),[1][2] Falsirechnung rsp. Falsi-Rechnung sind Methoden zur Berechnung von Nullstellen.
- Die ursprüngliche, historische Regula Falsi diente der Lösung einer linearen Gleichung mit Hilfe zweier „falscher“ Testwerte.
- Als numerische Methode, auch lineares Eingabeln genannt, dient die Regula Falsi als Iterationsmethode zur Ermittlung der Nullstelle reeller Funktionen. Sie kombiniert Methoden vom Sekantenverfahren und der Bisektion.
Das Regula-Falsi-Iterationsverfahren (Primitivform)

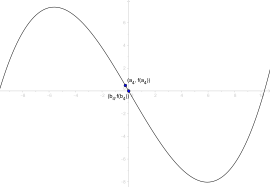
Das Regula-falsi-Verfahren startet mit zwei Stellen (in der Nähe der Nullstelle) und , deren Funktionsauswertungen , unterschiedliche Vorzeichen haben. In dem Intervall befindet sich somit nach dem Zwischenwertsatz (für stetiges ) eine Nullstelle. Nun verkleinert man in mehreren Iterationsschritten das Intervall und bekommt so eine immer genauere Näherung für die Nullstelle.




![{\displaystyle [a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9c4b788fc5c637e26ee98b45f89a5c08c85f7935)

Iterationsvorschrift
In Schritt berechnet man:

- .


Ist , so wird das Verfahren beendet, denn mit ist eine Nullstelle gefunden. Anderenfalls wählt man , wie folgt:




- falls und gleiches Vorzeichen haben sowie
- falls und gleiches Vorzeichen haben,





und geht damit in den nächsten Iterationsschritt.
Bemerkungen
- Die Berechnung des entspricht dem Anwenden des Sekantenverfahrens mit einer Iteration im -ten Intervall. Im Gegensatz zum Sekantenverfahren befindet sich in diesem Intervall aber stets eine Nullstelle.
- Geometrisch kann man als die Nullstelle der Sekante durch und deuten.
- liegt natürlich immer im Intervall .
- Konvergenz: Solange im -ten Intervall nicht strikt konkav bzw. konvex ist, also im Intervall ein Vorzeichenwechsel der zweiten Ableitung vorliegt, liegt superlineare Konvergenz vor.



![{\displaystyle \left[a_{k-1},b_{k-1}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/09ae57559c1843fd3d81a2e8dd0780ec4a040ab5)
- Visualisierung der Regula falsi
-

-

-

-

-





Verbesserung des Verfahrens
Ist konkav oder konvex im Intervall , hat die zweite Ableitung also überall im Intervall das gleiche Vorzeichen, so bleibt eine der Intervallgrenzen für alle weiteren Iterationen stehen, denn die Sekante liegt immer unterhalb bzw. oberhalb der Funktion. Die andere Intervallgrenze konvergiert jetzt nur noch linear gegen die Lösung.
![{\displaystyle [a_{k},b_{k}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/13f59f1660676e1ffeb6e604b7011896c643a81d)
Abhilfe schaffen die folgenden Verfahren.
Illinois-, Pegasus- und Anderson/Björck-Verfahren
Idee der Verfahren
Den verbesserten Verfahren liegt die folgende Idee zu Grunde: Falls sich die „linke“ Intervallgrenze im aktuellen Schritt nicht verändert – das heißt, dass die tatsächliche Nullstelle zwischen der „linken“ Grenze und der genäherten Nullstelle liegt –, multipliziert man mit einem Faktor und bringt den Funktionswert an der Stelle damit näher an Null.



Entweder verkürzt sich somit der Abstand der Näherung zur Nullstelle im nächsten Schritt oder die Nullstelle wird im nächsten Schritt zwischen der tatsächlichen Nullstelle und der „rechten“ Intervallgrenze genähert.
Im zweiten Fall werden dann einfach „rechts“ und „links“ für den nächsten Schritt vertauscht. Da der zweite Fall irgendwann – auch in konvexen Intervallen – immer eintritt, ist sicher, dass keine der beiden Intervallgrenzen bis zum Abbruch stehen bleibt. Somit ist die Konvergenz garantiert superlinear.
Algorithmus
Den folgenden Algorithmus haben diese Verfahren gemeinsam:

Dabei sind die Intervallgrenzen im -ten Schritt, und die Funktionswerte an den Stellen und . sind die Abbruchgrenzen und der Verkürzungsfaktor. steht hier für eine nicht näher spezifizierte, zweistellige Boolesche Funktion. Sinnvolle Funktionen wären hier die Disjunktion, die Konjunktion, die Identität des ersten und die Identität des zweiten Operanden. Im ersten Fall muss eine der beiden Abbruchgrenzen, im zweiten Fall beide, im dritten Fall lediglich und im vierten Fall unterschritten werden, damit falsch wird und das Verfahren abbricht.










Die unterschiedlichen Verfahren unterscheiden sich lediglich im Verkürzungsfaktor .
- Illinois-Verfahren

- Pegasus-Verfahren

- Anderson/Björck-Verfahren

Rekursive Implementierung des Pegasus-Verfahrens
Die zu untersuchende Funktion und die Abbruchkriterien:
epsx, epsf seien definiert f(x) sei definiert
Der Verkürzungsfaktor für das Pegasus-Verfahren:
m(f2, fz): return f2 ÷ (f2 + fz)
Der eigentliche, rekursive Algorithmus:
betterFalsePosition(x1, x2, f1, f2): z := x1 − f1 · (x2 − x1) ÷ (f2 − f1) // Näherung für die Nullstelle berechnen fz := f(z)
// Abbruchgrenze unterschritten?: z als Näherung zurückgeben if |x2 − x1| < epsx or |fz| < epsf then return z
// ansonsten, Nullstelle in [f(xz), f(x2)]?: „Links und Rechts“ vertauschen, Nullstelle in [f(xz), f(x2)] suchen if fz · f2 < 0 then return betterFalsePosition(x2, z, f2, fz)
// ansonsten: „verkürzen“ und Nullstelle in [x1, z] suchen return betterFalsePosition(x1, z, m(f2, fz) · f1, fz)
Die Methode, mit der das Verfahren für das zu untersuchende Intervall, gestartet wird:
betterFalsePosition(x1, x2): return betterFalsePosition(x1, x2, f(x1), f(x2))
Bemerkungen
- Die Konvergenz der Verfahren ist superlinear und mit der des Sekantenverfahrens vergleichbar.
- Durch die superlineare, garantierte Konvergenz und den relativ geringen Rechenaufwand je Iteration sind diese Verfahren bei eindimensionalen Problemen in der Regel anderen Verfahren (wie z. B. dem Newton-Verfahren) vorzuziehen.
Geschichte
Die Regula falsi zur Lösung einer linearen Gleichung
Die historische Regula falsi findet sich bereits in sehr alten mathematischen Texten, beispielsweise wird sie im Papyrus Rhind (ca. 1550 v. Chr.) angewandt.[3]
Unter den ältesten erhaltenen Dokumenten, die vom Wissen um die Methode des doppelten falschen Ansetzens zeugen, befindet sich die indisch-mathematische Schrift „Vaishali Ganit“ (ca. 3. Jahrhundert v. Chr.). Der altchinesische mathematische Text Die Neun Kapitel der mathematischen Kunst (200 v. Chr. – 100 n. Chr.) erwähnt den Algorithmus ebenfalls. In diesem Text wurde das Verfahren auf eine lineare Gleichung angewandt, sodass die Lösung direkt, also ohne Iteration, erreicht wurde. Auf den Bagdader Mathematiker, Philosoph und Arzt Qusta ibn Luqa (820–912) geht eine geometrische Begründung der Regula falsi zurück.[4] Leonardo da Pisa (Fibonacci) beschrieb das Verfahren des doppelten falschen Ansetzens in seinem Buch „Liber Abaci“ (1202 n. Chr.),[1] angelehnt an eine Methode, die er aus arabischen Quellen gelernt hatte.
Auch Adam Ries kannte die regula falsi und beschrieb die Methode wie folgt:
„wird angesetzt mit zwei falschen Zahlen, die der Aufgabe entsprechend gründlich überprüft werden sollen in dem Maße, wie es die gesuchte Zahl erfordert. Führen sie zu einem höheren Ergebnis, als es in Wahrheit richtig ist, so bezeichne sie mit dem Zeichen + plus, bei einem zu kleinen Ergebnis aber beschreibe sie mit dem Zeichen −, minus genannt. Sodann ziehe einen Fehlbetrag vom anderen ab. Was dabei als Rest bleibt, behalte für deinen Teiler. Danach multipliziere über Kreuz jeweils eine falsche Zahl mit dem Fehlbetrag der anderen. Ziehe eins vom anderen ab, und was da als Rest bleibt, teile durch den vorher berechneten Teiler. So kommt die Lösung der Aufgabe heraus. Führt aber eine falsche Zahl zu einem zu großen und die andere zu einem zu kleinen Ergebnis, so addiere die zwei Fehlbeträge. Was dabei herauskommt, ist dein Teiler. Danach multipliziere über Kreuz, addiere und dividiere. So kommt die Lösung der Aufgabe heraus.“[2]
Die Regula falsi als numerische Methode
Die ursprünglichen Schöpfer der entsprechenden numerischen Verfahren sind nicht bekannt. Die Illinois-Methode wurde 1971 veröffentlicht, mit einem Hinweis auf den möglichen Ursprung in den 1950er Jahren im Rechenzentrum der University of Illinois.[5] Die 1972 öffentlich beschriebene Pegasus-Methode wurde so benannt, weil unbekannte Autoren sie zuvor auf einem Röhrenrechner des Typs Pegasus eingesetzt hatten;[6] dieser Rechner war von der britischen Firma Ferranti Pegasus ab 1956 ausgeliefert worden.
Weblinks
Commons: Regula falsi – Sammlung von Bildern, Videos und Audiodateien
Einzelnachweise
- ↑ a b Leonardo da Pisa: Liber abbaci. 1202, Kapitel 13. De regula elcataym qualiter per ipsam fere omnes erratice questiones soluantur.
- ↑ a b Adam Ries: Rechenung auff der linihen und federn. 1522 (Siehe Matroids Matheplanet: Die regula falsi – Adam Ries’ wichtigste Rechenregel.).
- ↑ Arnold Buffum Chase: The Rhind Mathematical Papyrus. Free Translation and Commentary with Selected Photographs Transcriptions, Transliterations and Literal Translations by Arnold Buffum Chase, Editoren: Phillip S. Jones, Bruce E. Meserve, The National Council of Teachers of Mathematics, Classics in Mathematics Education A Series, 1979.
- ↑ Hans-im-Pech: Mathematik: Die regula falsi – Adam Ries’ wichtigste Rechenregel. In: Matroids Matheplanet – Die Mathe Redaktion. 26. Juni 2007, abgerufen am 31. Oktober 2020.
- ↑ M. Dowell, P. Jarratt: A modified regula falsi method for computing the root of an equation. In: BIT Numerical Mathematics. Band 11, Nr. 2. Springer, Juni 1971, ISSN 0006-3835, S. 168–174, doi:10.1007/BF01934364 (springer.com).
- ↑ M. Dowell, P. Jarratt: The “Pegasus” method for computing the root of an equation. In: BIT Numerical Mathematics. Band 12, Nr. 4. Elsevier, Dezember 1972, ISSN 0006-3835, S. 503–508, doi:10.1007/BF01932959 (springer.com).








